This is the documentation site for the Rosetta Platform, which is operated by technology firm REGnosys.
The platform comprises three types of components, respectively documented here.
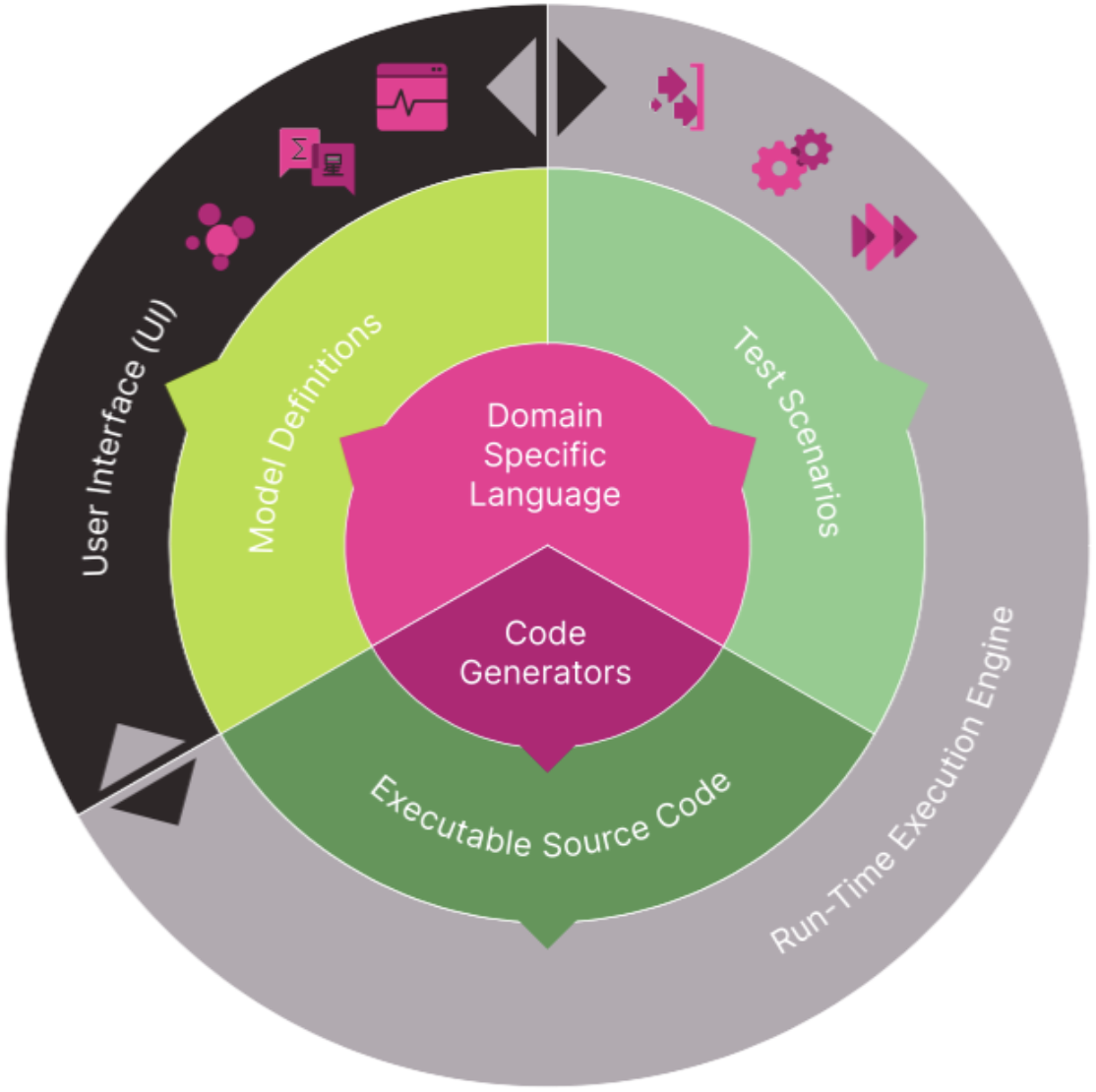
Rosetta DSL
The Rosetta DSL is an open-source project initially developed by REGnosys. REGnosys welcomes outside contributions that help keep it technology- and platform-agnostic. Code generators in several programming languages have already been contributed by the user community.
Projects
Model components are organised into projects in a source-control repository. Some projects are openly available on the platform, under license terms and a governance framework that reflect how their owners wish to control their distribution and contribution
Rosetta Products
The Rosetta Products are connected to the source-control repository holding all the model components. The Rosetta Products provide a complete model development kit allowing users to view or edit existing projects, create new ones, or use the models to develop new applications and services.